HPE Cloud Volumes が実現する新たなクラウドバックアップ 検証レポート 後編
2022年3月
※ 現在は終息しているサービスとなります。ご了承ください。
新たなクラウドバックアップとして注目の “HPE Cloud Volumes”。
実際に「ハイブリッドITインフラ」のディザスタリカバリー (以下、DR) やバックアップ先としてどのように活用できるのか、レプリケーションしたデータをどのようにクラウドと連携させるのか。
前編に引き続き、実機とライセンスを使って検証してみました。
-Agenda-
- ■ 続・HPE Cloud Volumes を使ってみた
- (1) HPE Cloud Volumes Backupを利用したバックアップソフト連携
- 1. バックアップストアの作成と Secure Client のダウンロード
- 2. Linuxサーバーに Secure Client をインストール
- 3. Veeam から Secure Client のLinuxを登録してバックアップ先を認識
- 4. バックアップを実施
- 5. リストアを実施
- (1) のシナリオのまとめ
- (2) HPE Cloud Volumes Block を利用したオンプレミス仮想サーバーのクラウド移行
- 1. 仮想マシンのデータ領域を HPE Cloud Volumes へレプリケーション
- 2. AWS への移行に合わせて仮想マシンを変更
- 3. VMware の仮想マシンをエクスポート
- 4. AWS 上で、VM Import で使用するための一時領域 (Amazon S3) を用意
- 5. EC2 (仮想サーバー) を作成し、HPE Cloud Volumes のボリュームを割り当て
- 6. 仮想サーバーのインポート用のポリシーを作成
- 7. インポート用ユーザーを作成し、ポリシーを割り当て
- 8. AWS CLI を使用して VM Import を実施
- 9. AWS AMI から EC2 インスタンスを作成
- 10. レプリケーションしたデータ領域を仮想サーバー (EC2) にマウント
- (2) のシナリオのまとめ
- ■ まとめ
続・HPE Cloud Volumes を使ってみた
前編に引き続き、HPE Cloud Volumes を実際に社内で試用し、操作感とメリットを検証してみましたので、ご紹介します。
後編では、以下の二つのシナリオをテストしてみました。
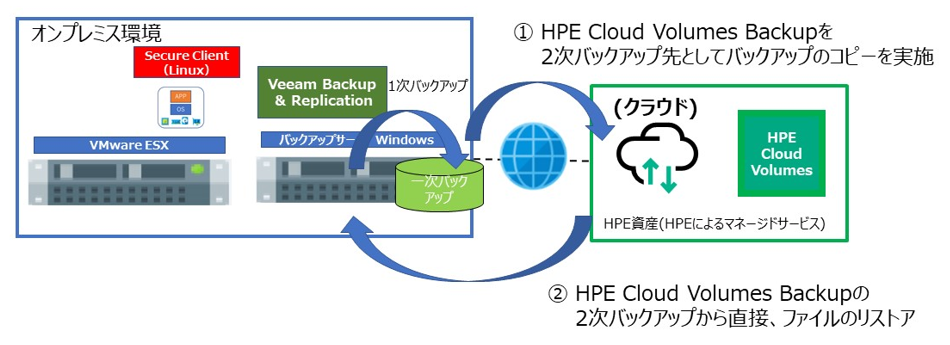
(1) HPE Cloud Volumes Backup を利用したバックアップソフト連携
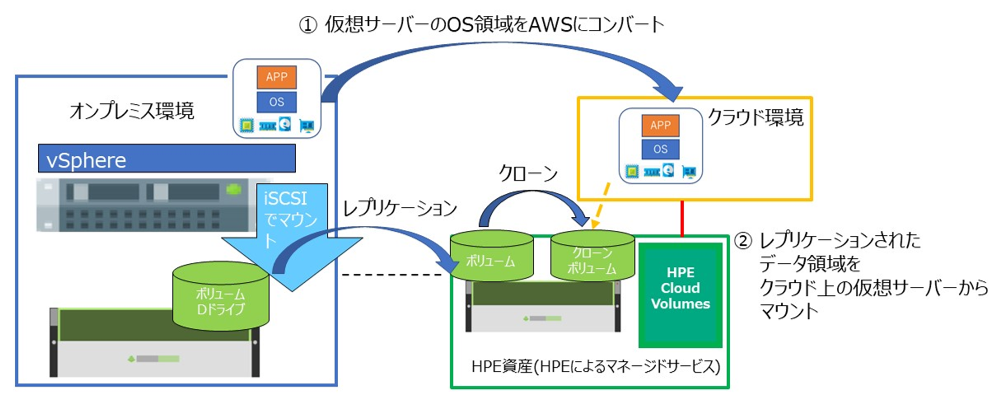
(2) クラウドからレプリケーションボリュームをマウントして利用
- 2022年1月に検証した時点での内容です。HPE Cloud Volumes の画面などは、将来的に変わる可能性がある旨、ご了承ください。
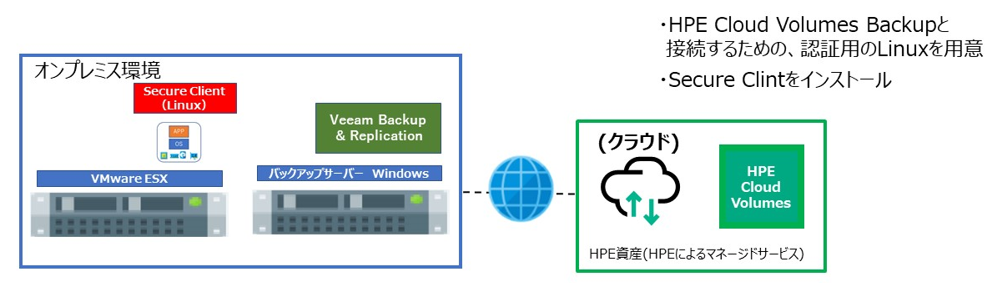
以下が今回、当社で検証に利用した環境のイメージ図です。
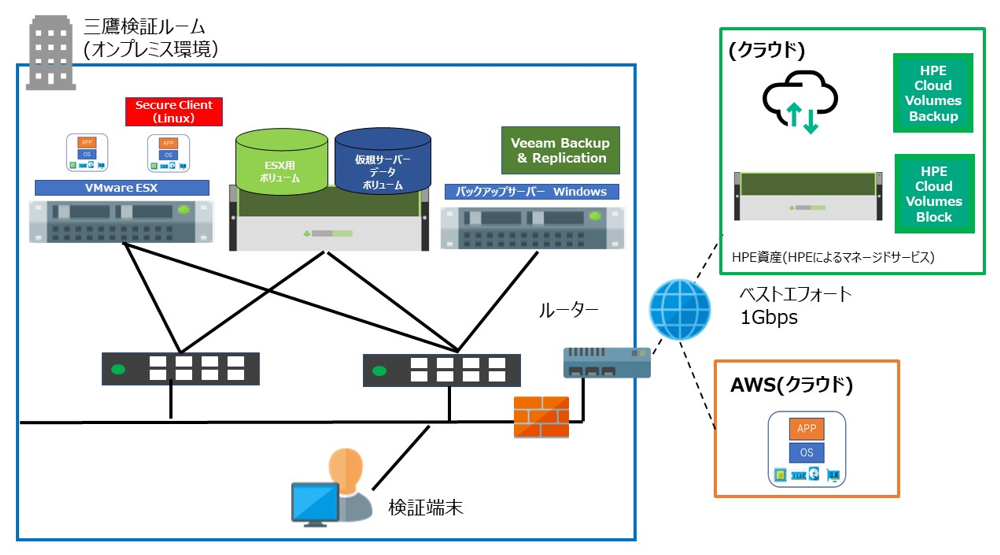
当社の検証ルームにある HPE Nimble Storage (CS1000) と DL380 Gen10 のバックアップサーバーを、ベストエフォート1Gbpsの回線を使用してインターネット接続して実施しています。
またクラウドには AWS (Amazon Web Services) を使います。
(1) HPE Cloud Volumes Backup を利用したバックアップソフトの連携
検証は、バックアップソフトとして Veeam Backup & Replication を使用し、以下のような流れで行いました。
- バックアップストアの作成と Secure Client のダウンロード
- Linux サーバーに Secure Client のセットアップ
- Veeam から Secure Client の Linux を登録して、バックアップ先を認識
- バックアップを実施
- リストアを実施
では、それぞれ画面をもとに解説していきます。
1. バックアップストアの作成と Secure Client のダウンロード
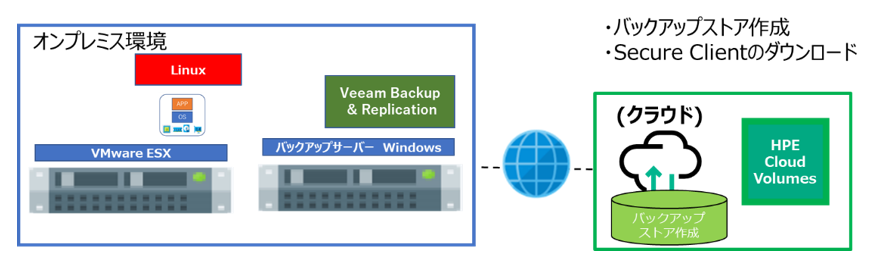
HPE Cloud Volumes にログインして、Backup Stores から新しいストアを作成します。
ボリューム作成時に表示されるユーザー名とパスワードを控えておきます。
ストアを作成すると、「Download the Secure Client」から、HPE Cloud Volumes Backup に接続するための Secure Client のzipファイルがダウンロードできます。
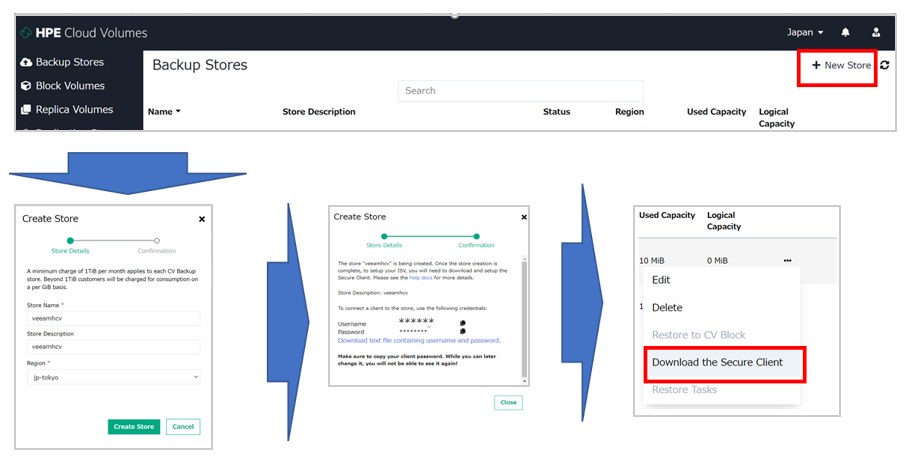
ダウンロードしたzipファイルには、以下のようにセキュリティー証明書と接続先の情報が記載されているファイルとプログラムが含まれています。

2. Linux サーバーに Secure Client をインストール
Secure Client 用に、以下のシステム要件を満たす Linux サーバーを用意します。

ダウンロードしたzipファイルを使用して、マニュアルの内容をもとに以下の流れでコマンドにて設定します。
- secureclient のユーザーを作成
- 展開するディレクトリ作成 (/opt/cloudvolumes/)
- 展開したファイルにアクセス権を設定
- 展開したファイルに実行ユーザーを追加
- 必要なポート (9386,9387,9388) をアクセス可能にする
- secureclient ユーザーでプログラムを実行
参考URL 該当ページ:https://docs.cloudvolumes.hpe.com/help/kts1584136344568/ (※ 2025年5月現在、製品終息のため、ページは確認できません)
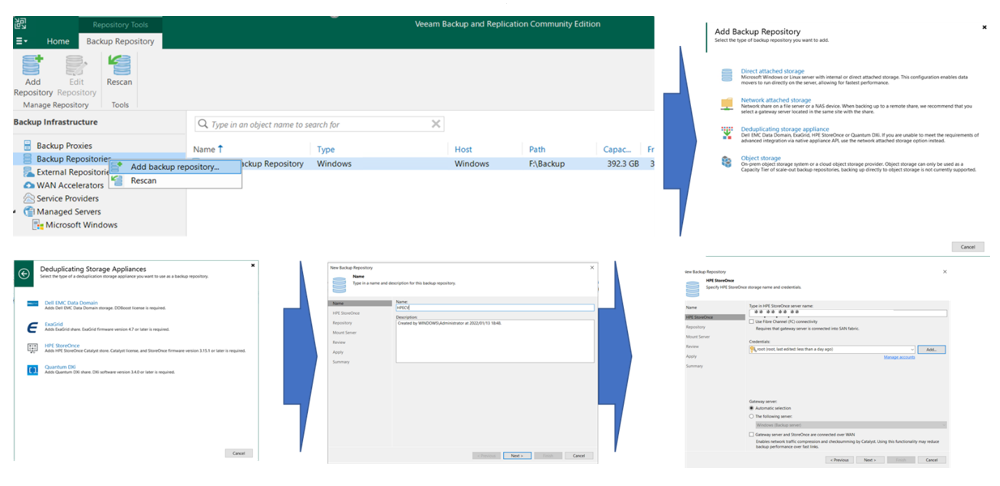
3. Veeam から Secure Client の Linux を登録してバックアップ先を認識
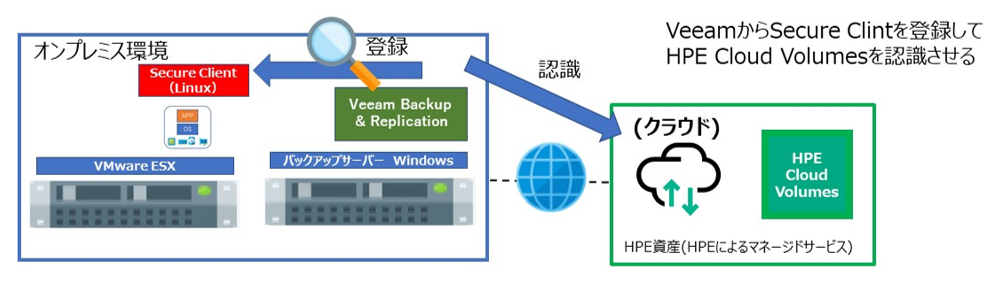
以下の内容で Veeam のウィザードで設定します。
- Backup Repository (保存領域) として「Deduplicating Storage Appliance」を選択
重複排除ストレージとして「HPE StoreOnce」を選択
Secure Client をインストールした Linux サーバーのIPアドレスを入力
- 認証情報に HPE Cloud Volumes のストア作成時に表示されるユーザー名とパスワードを入力
4. バックアップを実施
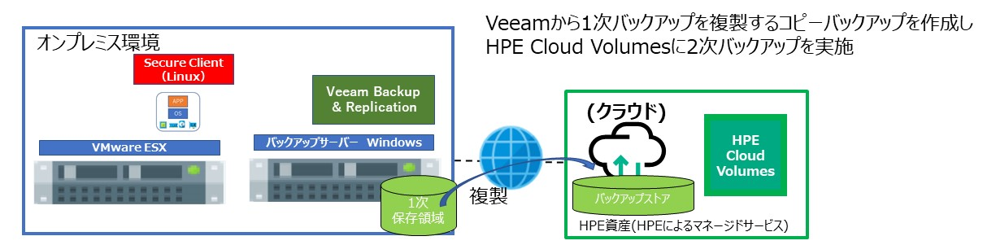
2次バックアップ先として HPE Cloud Volumes Backup を利用するため、1次バックアップのコピージョブを作成します。
バックアップのコピージョブとして、バックアップ先の選択で HPE Cloud Volumes のストアを選択する以外は通常の設定内容と同じです。
バックアップを実施すると HPE Cloud Volumes に使用されたディスク容量が表示されます。
重複排除が効いているため使用されているディスクは節約できます。
5. リストアを実施
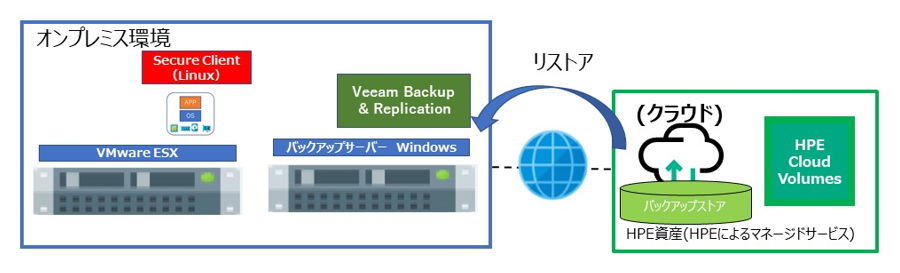
HPE Cloud Volumes Backup のバックアップからリストアをする場合は、HPE Cloud Volumes Backup へバックアップしたバックアップコピージョブを選択するだけで、後は通常のリストアの仕方と同じです。
(1) のシナリオのまとめ
HPE Cloud Volumes Backup は、対応するバックアップソフトを現在ご利用中であれば、バックアップ先として、後から簡単に追加できます。
Linux の SecureClient を作成する手間はありますが、それさえ用意できれば、クラウドへのバックアップ先を簡単に登録できます。
バックアップ先の登録も、仮想テープ装置の StoreOnce を追加するのと同じ感覚で操作できます。
HPE Cloud Volumes Backup は、ソース側で低帯域幅の重複排除が利用できます。
同じような仮想サーバーやファイルが多い環境ならストレージ使用量を抑えて、費用を節約した活用ができます。
重要度の高いファイルやフォルダのみをバックアップ対象として活用すれば、費用対効果のよいソリューションとして利用できると思います。
また、リストア時にかかる費用がないため、リストアテストなども実施しやすいのがよい点です。
参考:https://www.hpe.com/jp/ja/storage/cloud-volumes.html (※ 2025年5月現在、製品終息のため、ページは確認できません)
また、逆向きレプリケーションでも追加の費用がかからないのでテストがしやすく、将来的にはクラウドのデータをオンプレミスに戻すなどの使い方にも活用できると思います。
(2) HPE Cloud Volumes Block を利用したオンプレミス仮想サーバーのクラウド移行
続いて、オンプレミスで稼動している仮想サーバーを HPE Cloud Volumes Block を利用して、クラウドへ移行する作業について検証してみました。
本検証では、以下の仮想サーバーを移行対象としています。
- VMware の Windows 2016 Server の仮想サーバー
- Nimble のボリュームをデータ領域 (Dドライブ) として、iSCSIマウント
- アプリケーションは Microsoft SQL Server をデータ領域にインストール設定
検証は、以下のような流れです。
- 仮想サーバーのデータ領域のみ、HPE Cloud Volumes へレプリケーション
- AWS への移行に合わせて仮想サーバーの設定を変更
- VMware の仮想サーバーをエクスポート
- AWS 上で、VM Import で使用するための一時領域 (Amazon S3) を用意
- 仮想サーバー構成ファイルを一時領域 (Amazon S3) にアップロード
- AWS CLI で仮想サーバーのインポート用ユーザーを作成し、権限割り当て
- AWS CLI を使用して、VM Import を実施
- 移行した EC2 インスタンスのネットワークを変更
- レプリケーションしたデータ領域を仮想サーバー (EC2) にマウント
- 上記はクラウドサービスとして AWS を使用しての内容です。
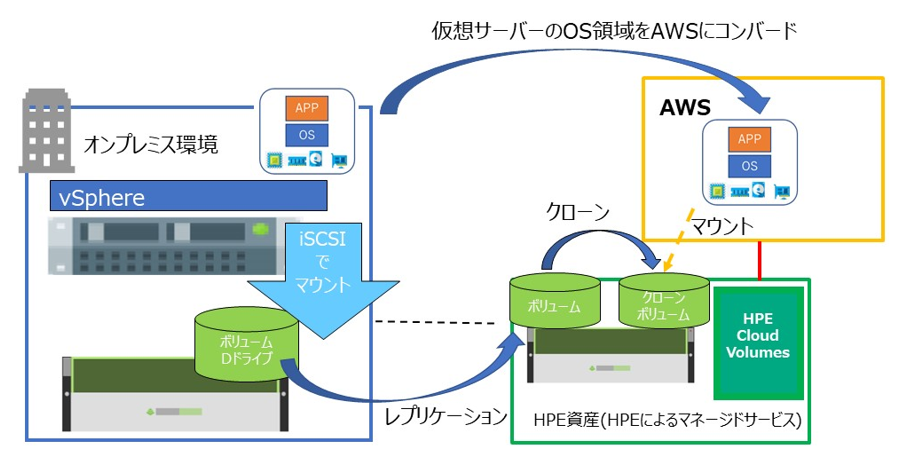
1. 仮想マシンのデータ領域を HPE Cloud Volumes へレプリケーション
前編で紹介したのと同様に、Nimble のボリュームを HPE Cloud Volumes にレプリケーションします。
今回は RDM-DB1 というデータベースのデータ領域をレプリケーション対象としています。
2. AWS への移行に合わせて仮想マシンを変更
先ほどと同じようにボリュームをレプリケーションし、レプリケーションからクローンを作成します。
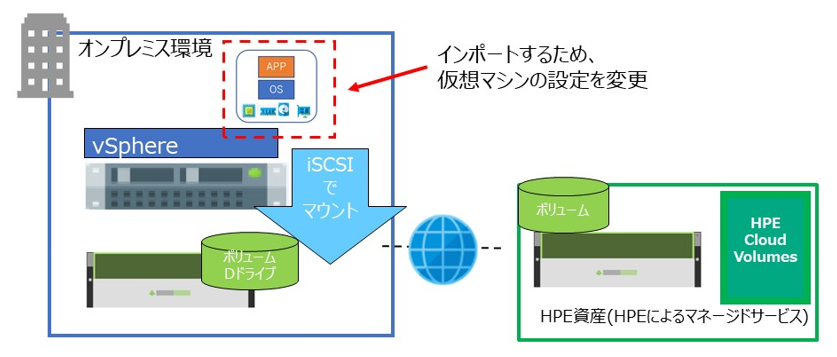
AWS に仮想マシンをインポートする場合、設定変更が必要になります。
本検証では VM Import を使用しますので、AWS の下記ページを参考に、設定変更を行ってください。
サポートされる仮想マシンイメージや、OSなどの情報も記載されています。
ライセンスの取り扱いなどについても記載されているので、作業前に確認しておくと良いでしょう。
作業前にバックアップや仮想サーバーのクローン作製などでバックアップを取得しておくことがお勧めです。
コンバート前に Windows Defender などウイルス対策ソフトを無効にすることや、VMware Tools のアンインストールなどを行います。
3. VMware の仮想マシンをエクスポート
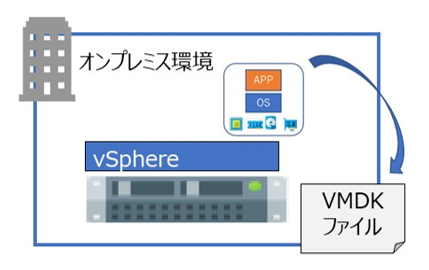
VMware 標準のエクスポート機能を利用して、移行する仮想マシンをエクスポートします。
利用できる形式ならびにサポートOSは、以下のURLに記載があります。
4. AWS 上で、VM Import で使用するための一時領域 (Amazon S3) を用意
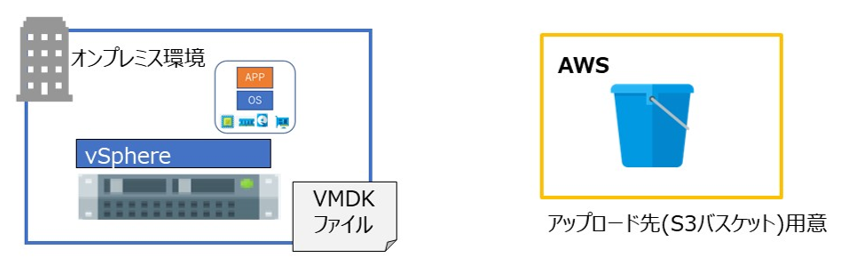
仮想マシンのインポート用の領域としてS3バケットを作成します。
今回は、「yrltest-vmimport-s3」という名前で作成しています。
5. EC2 (仮想サーバー) を作成し、HPE Cloud Volumes のボリュームを割り当て
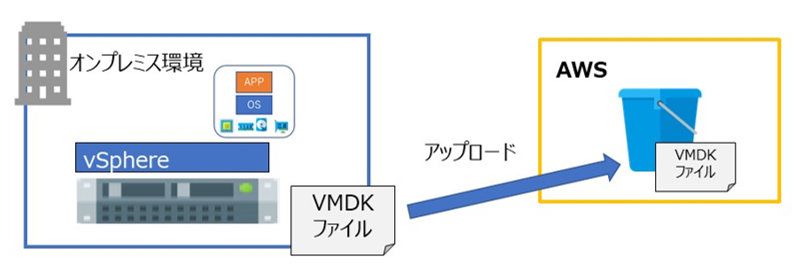
「3.VMwareの仮想マシンをエクスポート」で出力したVMDKファイルを、作成したS3バケットアップロードします。
ブラウザーでアップロードできるサイズは160GBまでとなりますので、VMDKファイルが16GBを超える場合は AWS CLI を使ってアップロードする必要があります。
以下は AWS CLI を利用してアップロードした場合のコンソール画面です。

アップロード時に20MB/sec出ています。
検証環境のインターネットのアップロード速度が150Mbpsから200Mbpsなので、十分な速度で転送できていることがわかります。
ブラウザー利用時より、かなり高速に転送できます。
6. 仮想サーバーのインポート用のポリシーを作成

Identity and Access Management (IAM) で「ポリシー」から「ポリシー作成」にて、インポート用ユーザーに適用するポリシーを作成します。
7. インポート用ユーザーを作成し、ポリシーを割り当て
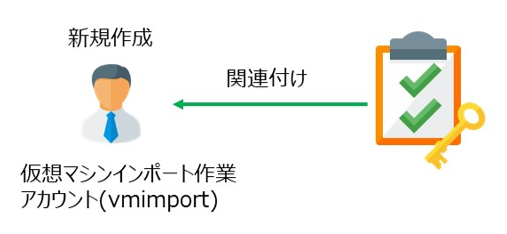
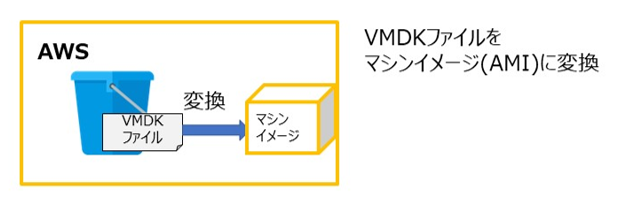
8. AWS CLI を使用して VM Import を実施
AWS CLI を使用して、コマンド設定をします。
必要なツールは以下のURLからダウンロードできます。
ツールのインストールは、ウィザードで「次へ」のクリックをしていけばよく、特に設定するところはありません。
実際のインポート操作は下記URLを参照してください。
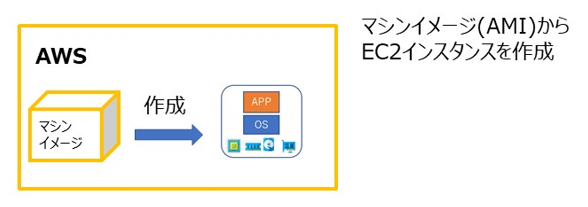
9. AWS AMI から EC2 インスタンスを作成
AWS AMI から EC2 インスタンスを作成します。
ネットワーク設定で以下のように HPE Cloud Volumes に接続できる仮想ネットワークを割り当てます。
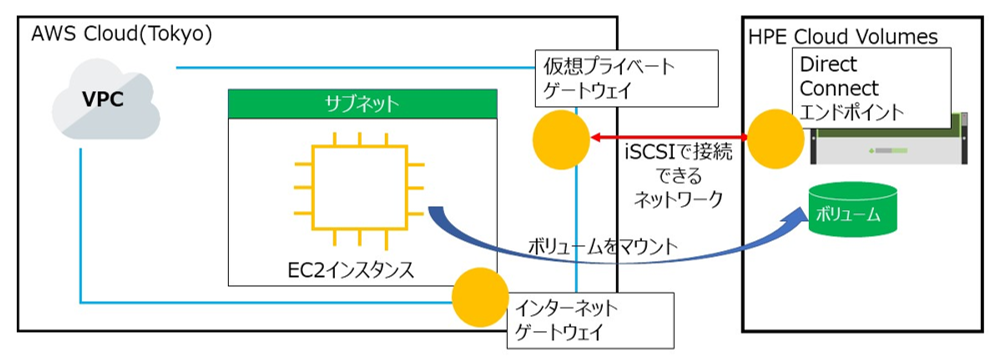
後は、ウィザードを通常通り進めていくだけで設定終了です。
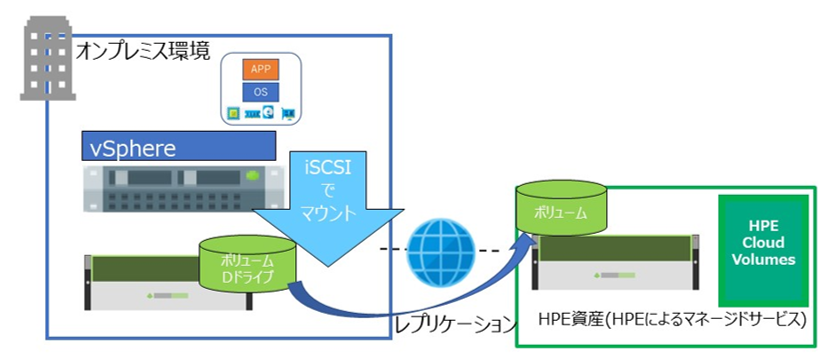
10. レプリケーションしたデータ領域を仮想サーバー (EC2) にマウント
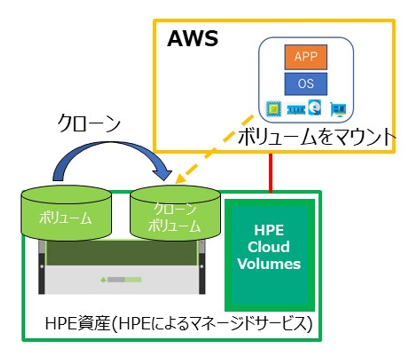
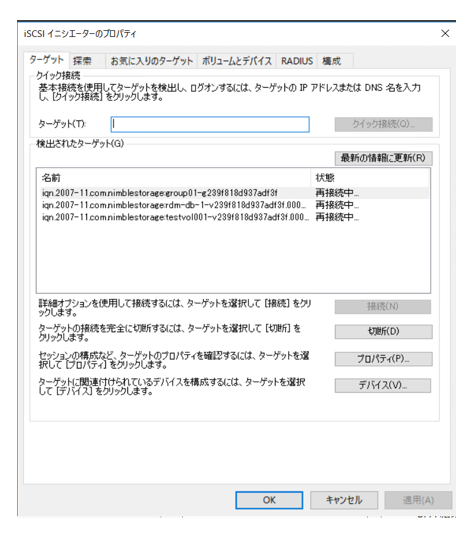
移行前のiSCSIターゲット情報などがあれば削除してきれいにします。
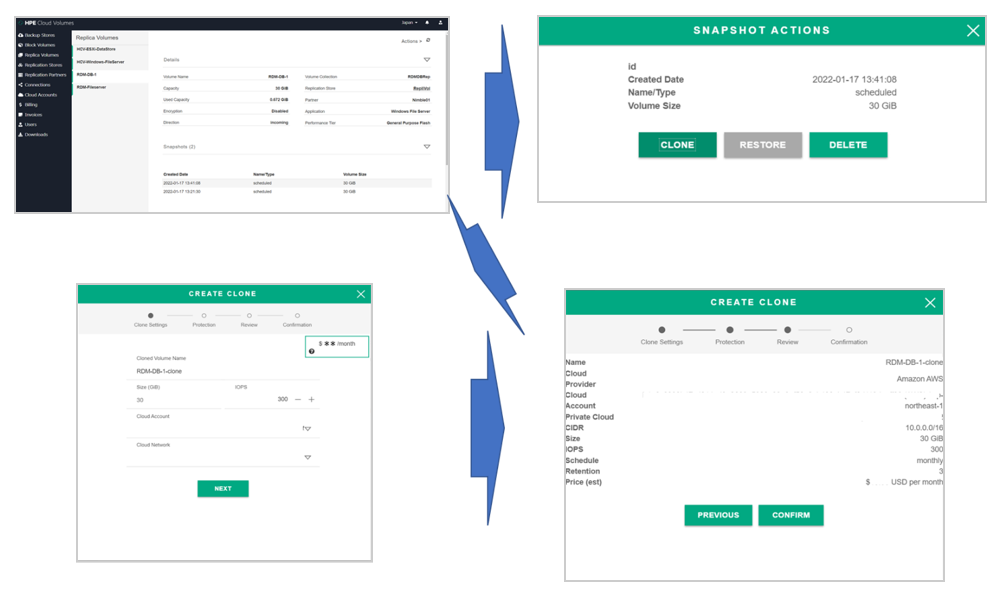
レプリケーションしたボリュームのクローンを作成し、接続するネットワークで AWS のVPCを選択します。
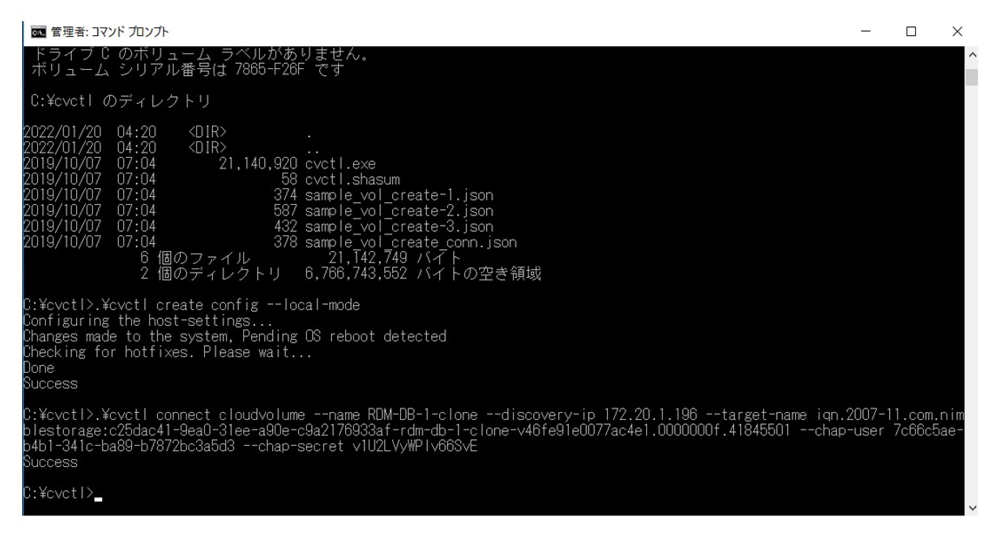
該当のボリュームを移行により作成した EC2 インスタンスにマウントします。
前編で紹介したように、コマンドラインからボリュームをアタッチします。
新しいボリュームとして、ディスクの管理で表示されますので、移行前と同じボリュームラベル (Dドライブ) を割り当てます。
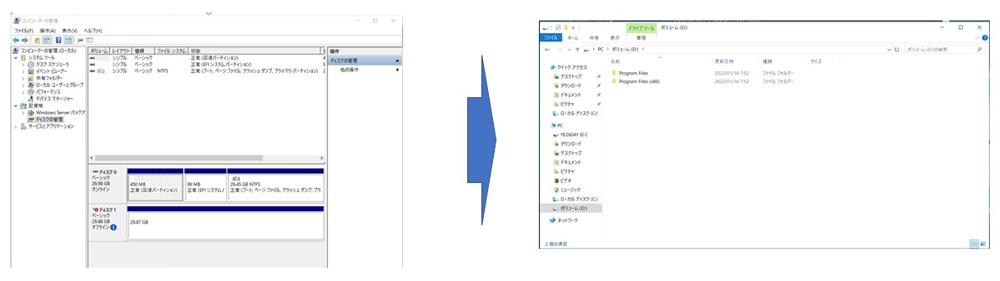
新しいデータ領域は、移行前と同じように利用できます。
(2) のシナリオのまとめ
この方式でオンプレミスからクラウドに移行した場合、容量の大きなデータ領域は HPE Cloud Volumes を利用することで、VM Import で移行する対象はOS領域のみとなり、停止時間を少なくしてスムーズに行えます。
検証においても時間がかかる工程は、クラウドへのアップロード時間でした。
例えば、OS領域が100GB、データ領域が1000GBの仮想サーバーとすると、全体で1.1TBの容量となります。
これを今回の検証環境に当てはめると、アップロード速度が20MB/sec程度でしたので、すべてアップロードするなら15.5時間くらいかかります。
これが、OS領域だけなら、1.5時間くらいでアップロードできます。
大容量のデータ領域は、HPE Cloud Volumes のレプリケーションスケジュールを利用することで、システムを稼動させながら HPE Cloud Volumes にデータレプリケーションが行えるので、クラウド移行のハードルを下げられると思います。
移行作業に関しても、仮想サーバーのコンバートや移行した仮想サーバーへの HPE Cloud Volumes のマウントも一度手順を理解し、手順書が用意された環境であれば、スムーズに作業できると感じました。
現在はオンプレミスを利用していても、将来的に順次クラウドへ移行など考えているケースや、クラウド上で現在の本番環境と同じ検証環境を作りたい場合は、この移行方法が役にたつと思います。
クラウドからオンプレミスへ戻す場合は、データ領域を逆レプリケーションできます。
そのため、必要に応じて、クラウドからオンプレミス利用に切り替えることもできるので、柔軟性に富んだ運用方法が可能です。
まとめ
今回の検証で、HPE Cloud Volumes を利用して、オンプレミスとクラウドとの連携が簡単にできることが確認できました。
オンプレミスとクラウド環境にはそれぞれの良さがあり、どちらに対しても柔軟に移行できることがハイブリッドITには求められます。
当面はネットワークやアプリケーションの制約などのため、オンプレミスでの利用が必要な仮想サーバーも、将来的にはクラウド移行をしたい場合もあるかと思います。
そのようなケースでは、HPE Nimble Storage を利用した仮想基盤で構築していると、HPE Cloud Volumes を利用してクラウド移行もスムーズにできるため、柔軟なITインフラになると思います。
お気軽にお問い合わせください
横河レンタ・リースのレンタルアップ中古PCを法人向け、個人向けに販売するサイト。
毎日約1000台返却される法人向けレンタルPCを当社独自の品質基準でリフレッシュし、中古PC・中古パソコンを特価で提供しています。

